The research origins of Stable Diffusion

Patrick Esser is a Principal Research Scientist at Runway, leading applied research efforts including the core model behind Stable Diffusion, otherwise known as High-Resolution Image Synthesis with Latent Diffusion Models.
In this interview, we spoke to Patrick about his research process, how he’s building his team, and what the future of image and video generation might look like.
As an experienced researcher in generative models for image and video synthesis, what do you see as your biggest challenges?
I think for products, we’re on the verge of the quality that we need. For Stable Diffusion for image generation or other models, you can get really high quality outputs out of them. But at the same time, it's not 100% consistent.
The goal is to have a really easy interface where you type what you think, and get the perfect output as you imagine it. We are not quite there yet. It’s becoming easier to do that, but it still requires a bit of work on how you formulate your thoughts, and how you write the prompt to get the best outputs of the model. There's definitely still room for improvement there.
From the interface perspective, do you think the best way to interact with these models is still using language? Will text become obsolete in the future?
Two years ago, I actually thought that text really might not be the way we were heading because it was too inaccurate. But it seems like the better we get with the models, we see that, actually, we can keep using text. Really good models really understand language well and it becomes feasible.
It looks like we’re definitely moving towards more text-based interfaces. I think for some tasks, it's still more convenient to have a more direct visual interaction where you paint something, or specify where you want to edit something. I still don't think we should force everything to be text now, just because we can.
Can you tell us the origins of the paper and the work behind Stable Diffusion?
There’s quite a big history there.
I think broadly, a big question is, how do you represent images to a computer? Because the basic way is just pixel-wise, a grid of pixels that has the intensities for the different colors. But it’s usually not very useful, because it doesn’t tell you what's in the picture.
So a larger topic is, how can you learn better representations for images that are more useful for downstream tasks? This has been done for a lot of analysis tasks, where you try to figure out what's in an image.
What I worked on for the last four years with my co-author Robin and other collaborators from the CompVis group was, how can we learn representations that are more useful to help us synthesize images?
We also worked on training transformers using VQGAN, which went in the direction where we showed that by learning a better representation of images (in that case it was a discrete representation), we can then apply powerful models like transformers (which were very good at that time), to better synthesize images. Then it was really a natural evolution with diffusion models coming along, which are a little different approach to synthesize data. It was natural to look in that space. We knew this was a really good approach for synthesizing; how can we learn good representations at the top for those models? That’s what that paper explored.
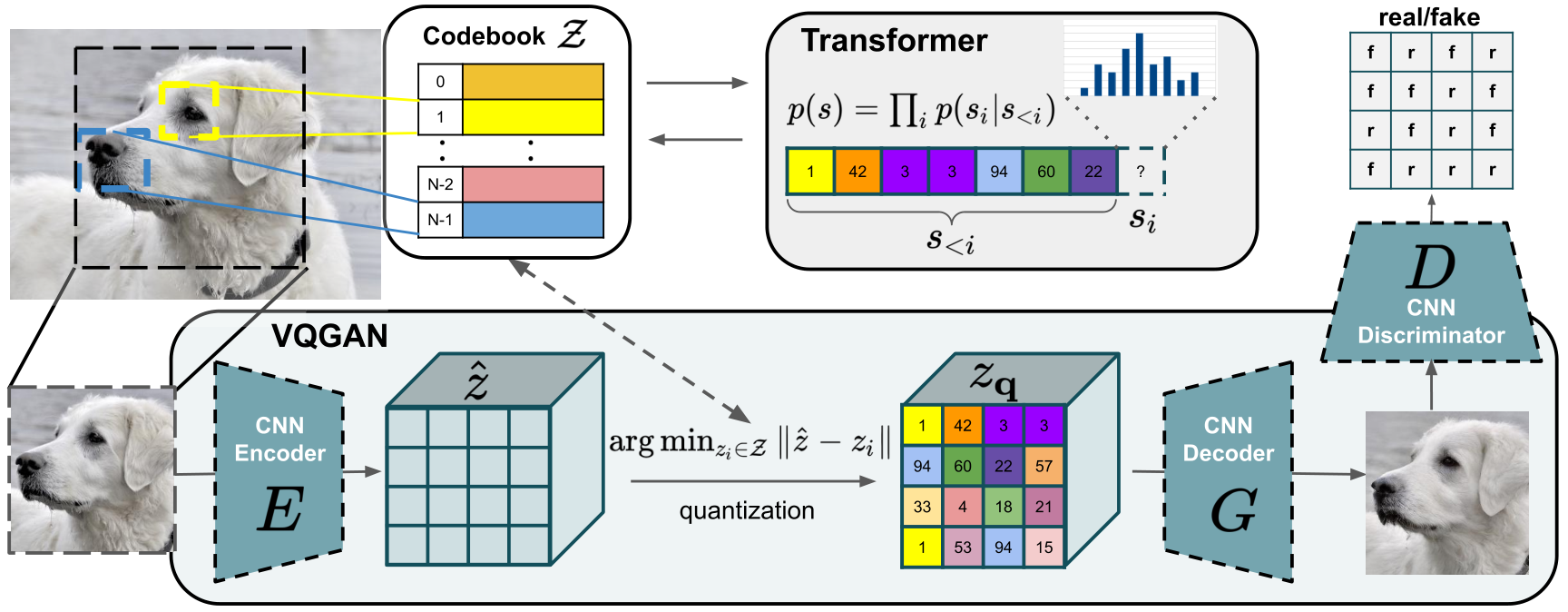
When we wrote that paper we showed that it actually works, nicely! And we got really promising results on our smaller scale. It showed us that it’s really effective for synthesizing images for different tasks. Then it was like - can we scale this up? And that led us to Stable Diffusion. It is really the same model, slight changes but not too essential. Just on a bigger scale in terms of our resources.

What user frustration do you think you're hitting on with your research? Like, where is the block between the user interest and what's available on the market?
I think it addresses a very essential need, which is that everybody wants to express themselves creatively, but especially visually. Drawing takes a lot of practice. Our work opens up generating visual content for so many people. Your interface is not your hand drawing things; it's your thoughts that you type into a text box and turn into a visual representation of your thoughts and ideas. I think that's really a powerful thing.
What are you excited about?
I'm always excited watching the research area and what’s happening. You never know. Some days you can wake up, and some great new research is out that changes the world and you have to rethink everything.
It’s a great time. We released Stable Diffusion openly for everybody to use, and it’s been beautiful to see what creative work people have pulled off. We will also build upon it, and are specializing it towards other applications. I personally work a lot on bringing it to the video domain.
#stablediffusion text-to-image checkpoints are now available for research purposes upon request at https://t.co/7SFUVKoUdl
— Patrick Esser (@pess_r) August 11, 2022
Working on a more permissive release & inpainting checkpoints.
Soon™ coming to @runwayml for text-to-video-editing pic.twitter.com/7XVKydxTeD
I'm really excited about exploring both the editing side, and then the application side of the models. I think there are lots of possibilities of integrating it into existing workflows while also enhancing traditional video editing just with the image model.
On the other hand, I think we will also look at coming up with equivalent or similar models that directly synthesize videos in the beginning, small animations.
What do you see as the value of open-sourcing research and publishing?
I think it's huge because it means more people are working on it, and more people are having access to it.
There are so many ideas that one could pursue. It’s not that we're running out of ideas, we’re mostly running out of time to follow up on them all. By open sourcing our models, there's so many more people available to explore the space of possibilities.
Do you see a world where multimodal models will become more dominant?
I can't predict the future, but I could definitely imagine a big model that's trained on diverse data that really generalizes. That’s where a lot of the power comes from. And in that sense, if we train a model to solve different tasks, that usually improves all of them, or at least the generalization capability.
I could definitely imagine that we might have more explicitly multimodal models, which is not limited to synthesizing or analyzing. It might work in all the ways simultaneously. With Stable Diffusion, we use an existing model to represent the text that’s being imputed into the model. We then use the CLIP model from OpenAI, which learns a representation of images, and text, which are compatible. What this ultimately enables is a similar encoding of images and text that’s useful to navigate.
You’re building a research team at Runway. What are you looking for in the researchers you hire?
The most concise summary is that I like people who really dive in, and are okay with uncertainty. Often in research there are the open questions. That’s why it’s called research, because we're entering territory where we don't have the answers and it's easy to get trapped in a loop where you consider all possibilities that you could try and experiment with. Spending so much time in that loop, you might not actually do the real experiments, and get the real experience of what works, what doesn't work.
You have to be okay with uncertainty. It's not like we're going to figure out everything. There are so many parameters to train models and choices for different techniques or components.
In an ideal world, we would do the full-on scientific thing and evaluate all of those choices. But it just quickly becomes exponential explosions, because it's a combination of all the different things. You can’t, in those complex systems, analyze them independently. You would have to go through all combinations to see what combinations work, instead of analyzing single components in isolation.
So I think that can be daunting, but a great team member shouldn’t be frightened or overanalyze it too much. I think we just need to experiment.
How are you hoping to communicate this research to the public? What are we missing when it comes to understanding where this space is headed?
I don’t think the public are missing much.
Sometimes there are misunderstandings about the relationship between data that's used to train models, and the model itself that we get as an end product. I think that relationship is actually difficult to describe, because training the model and producing it, really depends on the training data we use to train the model.
What one might suspect is that the model somehow uses specific data points in the training set to produce its output or maybe that it can only produce those. But what we really see is that the models generalize, and they can actually produce more diverse content than what they’re trained on. They can make interesting connections there.
So generally, the topic of generalization is hard to objectively grasp. I think we will get used to it just by seeing how things work. Right.
When it comes to your research, how are you measuring your success?
Measuring success is really difficult. It can be on different levels. It can be about you personally, or you as a team. If there’s an important research question to you, and you make progress on that, and you answer something, that's great.
The other question is about your impact. You have to measure how many people your research affects. That’s really hard to predict. I definitely worked on papers where I thought I was finding something really interesting, and people would want to know about this, but when the research came out, it didn’t seem to have much of an impact. I think sometimes you can get stuck in your own mindset about what’s interesting.
For me, if I see people taking some of my work and building something else, that’s a great measurement of success.
Released my "Image Variations" version of Stable Diffusion. Get the code and models, along with some basic instruction, in my GitHub repo: https://t.co/t6o3BxJfmf pic.twitter.com/5cK6QhPzAs
— Justin Pinkney (@Buntworthy) September 5, 2022
W.I.P. collage tool for stable diffusion pic.twitter.com/CYWMBhsHn4
— Gene Kogan (@genekogan) August 4, 2022
Fantasy art walkthrough using #stablediffusion #img2img. This is the culmination of a week of experimentation, lots of tips and tricks to have control over the composition and details! pic.twitter.com/yTXCuU0zW9
— Patrick Galbraith (@P_Galbraith) August 29, 2022
why settle for a few images from #stablediffusion when you can slowly walk your way around the sample space and create hyponotic videos you can't look away from? In this 2min video (~1hr to render on A100) I'm smoothly interpolating between random noise inputs into the model. pic.twitter.com/A4Ue1pqoMo
— Andrej Karpathy (@karpathy) August 16, 2022
Anything you want to add?
It’s definitely an interesting time to be in the field, because we’re really hitting a threshold where we move from academic research to the real possibility of using those techniques in a broader context, and seeing really good products with higher quality.